

این سند جامع که توسط گوگل منتشر شده، یکی از بهترین و کاربردیترین راهنماهای دنیا برای تسلط بر هنر پرامپت نویسی (Prompt Engineering) است. نکات و اصولی که در این آموزش یاد میگیرید، although برخی تنظیمات پیشرفته برای پلتفرمهای تخصصی گوگل (مانند AI Studio و Vertex AI) توضیح داده شده، اما اکثر قوانین و تکنیکها جهانی هستند و برای همه مدلهای هوش مصنوعی،ChatGPT, Gemini, Claude, Midjourney و دیگران، قابل اجرا و فوقالعاده کاربردی هستند.
گوگل به درستی در این سند توضیح میدهد که نیازی به دانشمند بودن نیست! مهندسی پرامپت یک فرآیند آزمون و خطا است که با یادگیری اصول اولیه و تمرین مداوم، هرکسی میتواند به یک متخصص تبدیل شود. این کتابچه الکترونیکی، مسیر آن یادگیری را برای شما هموار میکند.
دانلود فایل آموزش به زبان اصلی اینجا
دانلود PDF به زبان فارسی اینجا
وقتی درباره ورودی و خروجی یک مدل زبانی بزرگ (LLM) فکر میکنیم، ورودی اصلی معمولاً یک دستور متنی یا «پرامپت» است. پرامپت چیزی است که مدل از آن برای تولید یک خروجی مشخص استفاده میکند.
شما نیازی نیست یک دانشمند داده یا مهندس یادگیری ماشین باشید – هر کسی میتواند یک پرامپت بنویسد.
اما طراحی پرامپت مؤثر کمی پیچیده است. عوامل زیادی روی کیفیت پاسخ مدل تأثیر دارند، مثل نوع مدل، دادههای آموزشی، تنظیمات مدل، انتخاب کلمات، سبک و لحن و ساختار متن. بنابراین، مهندسی پرامپت یک فرایند تکراری است و پرامپتهای ضعیف میتوانند منجر به پاسخهای مبهم یا اشتباه شوند.
وقتی با چتباتهایی مثل Gemini یا ChatGPT کار میکنید، اساساً پرامپت مینویسید. اما این مقاله روی پرامپتنویسی برای مدل Gemini در Vertex AI یا با استفاده از API تمرکز دارد، چرا که این روش امکان کنترل تنظیماتی مثل دما و سایر پارامترها را میدهد.
در ادامه، ما تکنیکها و نکات کاربردی مهندسی پرامپت را بررسی میکنیم تا به شما کمک کنیم شروع کنید و به مرور یک متخصص پرامپت شوید. همچنین چالشهای احتمالی در این مسیر را هم مرور خواهیم کرد.
یک LLM اساساً یک موتور پیشبینی است. مدل، متن را به صورت توکن به توکن دریافت میکند و سعی میکند توکن بعدی را پیشبینی کند، با توجه به دادههایی که در طول آموزش دیده است.
وقتی پرامپت مینویسید، در واقع دارید مدل را برای تولید توالی درست توکنها هدایت میکنید. مهندسی پرامپت یعنی طراحی پرامپتهایی با کیفیت بالا تا مدل خروجی دقیق و مرتبط بدهد. این فرایند شامل آزمایش، بهینهسازی طول پرامپت و ارزیابی سبک و ساختار متن نسبت به وظیفه مورد نظر است.
پرامپتها میتوانند برای کارهای مختلفی مثل خلاصهسازی متن، استخراج اطلاعات، پرسش و پاسخ، طبقهبندی، ترجمه زبان، تولید کد و مستندسازی کد استفاده شوند.
برای شروع، معمولاً ابتدا مدل مورد نظر را انتخاب میکنید. پرامپتها ممکن است نیاز داشته باشند متناسب با مدل تنظیم شوند، چه مدل Gemini در Vertex AI باشد، چه GPT، Claude یا یک مدل متنباز مثل Gemma یا LLaMA.
در کنار پرامپت، تنظیمات مدل مثل دما و سایر پارامترها هم روی خروجی تأثیر دارند و نیاز به آزمایش دارند.
بعد از انتخاب مدل، باید تنظیمات خروجی آن را مشخص کنید. اکثر LLMها گزینههای مختلفی دارند که میتوانند روی نتیجه نهایی تأثیر بگذارند.
طول خروجی:
تعداد توکنهایی که مدل تولید میکند روی مصرف منابع، زمان پاسخ و هزینهها تأثیر دارد. طول خروجی بیشتر، محاسبات بیشتری لازم دارد و هزینه را بالا میبرد. کوتاه کردن طول خروجی باعث نمیشود مدل کوتاهتر یا خلاصهتر پاسخ دهد، بلکه بعد از رسیدن به محدودیت، تولید توکنها متوقف میشود.
کنترل نمونهگیری (Sampling):
مدلها به طور دقیق یک توکن واحد را پیشبینی نمیکنند، بلکه احتمال هر توکن را محاسبه کرده و سپس از میان آنها نمونهگیری میکنند.
دما (Temperature):
دما میزان تصادفی بودن انتخاب توکن را تعیین میکند. دمای پایین باعث پاسخهای قطعیتر و دمای بالا منجر به پاسخهای متنوعتر و خلاقانهتر میشود. دمای صفر یعنی مدل همیشه محتملترین توکن را انتخاب میکند، اما دمای بالا باعث میشود طیف وسیعتری از پاسخها تولید شود.
کنترل دمای مدل Gemini شبیه تنظیم دمای softmax در یادگیری ماشین است. دمای پایین، قطعیت بالاتری دارد و دمای بالا، تنوع پاسخ را افزایش میدهد، مخصوصاً زمانی که میخواهید خروجیهای خلاقانه یا غیرمنتظره بگیرید
اگر دنبال ابزارهای متنوع و کاربردی هوش مصنوعی هستید، ما در یک صفحه همه آنها را بهصورت دستهبندیشده جمعآوری کردهایم. همین حالا ببینید
مدلهای زبانی بزرگ (LLM) طوری طراحی شدهاند که بتوانند دستورالعملها را دنبال کنند و با توجه به حجم زیادی از دادهها، پاسخ تولید کنند. اما هیچ مدلی کامل نیست؛ هر چه پرامپت شما واضحتر و شفافتر باشد، مدل بهتر میتواند پیشبینی کند که متن بعدی چه خواهد بود.
علاوه بر این، تکنیکهای خاصی وجود دارد که با درک نحوه آموزش و عملکرد LLMها، کمک میکند نتایج دقیقتر و مرتبطتری از مدل دریافت کنید.
حالا که با مفهوم مهندسی پرامپت آشنا شدیم، بیایید به برخی از مهمترین تکنیکهای پرامپت نگاه کنیم:
پرامپت زیرو-شات سادهترین نوع پرامپت است. در این روش، تنها یک توضیح کوتاه از وظیفه و مقداری متن به مدل داده میشود تا پاسخ تولید کند. این متن میتواند یک سؤال، شروع یک داستان یا دستورالعمل کوتاه باشد. نام «زیرو-شات» هم به همین دلیل است؛ یعنی بدون ارائه نمونه یا مثال.
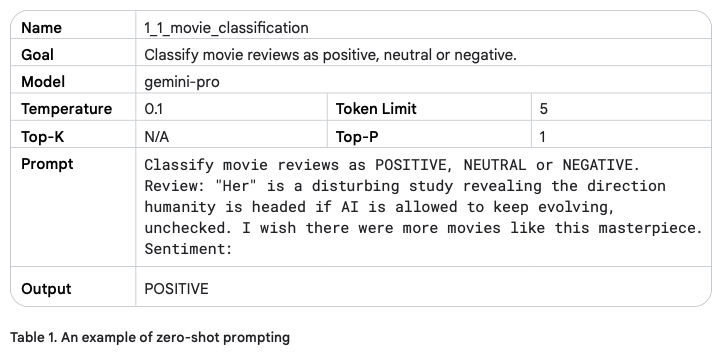
برای نمونه، میتوانید از محیط آزمایشی Vertex AI Studio استفاده کنید تا پرامپتهایتان را تست کنید. جدول زیر یک مثال پرامپت زیرو-شات برای طبقهبندی نقدهای فیلم را نشان میدهد.
استفاده از جدول، روشی عالی برای مستندسازی پرامپتها است. معمولاً پرامپتها قبل از استفاده در کد، چند بار اصلاح و تکرار میشوند، بنابراین مهم است که کار مهندسی پرامپت را به شکل منظم و ساختاریافته پیگیری کنید. بخش بهترین شیوهها در ادامه مقاله، توضیح بیشتری درباره «مستندسازی پرامپت» میدهد.
در این مثال، دمای مدل روی مقدار پایین تنظیم شده است، چون نیازی به خلاقیت بالایی نداریم. همچنین از مقادیر پیشفرض Top-K و Top-P مدل Gemini-pro استفاده میکنیم که عملاً هر دو تنظیم را غیرفعال میکند. به خروجی تولیدشده دقت کنید: کلمات مثل “disturbing” و “masterpiece” میتوانند پیشبینی مدل را کمی چالشبرانگیزتر کنند، چون هر دو در یک جمله آمدهاند.
مثال پرامپت زیرو-شات:
گاهی پرامپت زیرو-شات به تنهایی کافی نیست و مدل نمیتواند دقیقاً آنچه میخواهید را تولید کند. در این مواقع، ارائه نمونهها یا مثالها در پرامپت میتواند کمک بزرگی باشد. این کار منجر به ایجاد پرامپتهای تک-شات و چند-شات میشود.
پرامپت تک-شات (One-shot)
در این روش، فقط یک مثال ارائه میشود. مدل از روی این مثال یاد میگیرد که چه خروجیای از آن انتظار دارید و سعی میکند عملکرد مشابهی ارائه دهد. نام «تک-شات» هم به همین دلیل است؛ یعنی تنها یک نمونه برای راهنمایی مدل وجود دارد.
پرامپت چند-شات (Few-shot)
در این روش، چندین مثال ارائه میشود. این کار به مدل کمک میکند تا الگوها و ساختار مورد نظر را بهتر درک کند و خروجیهای دقیقتر و مرتبطتری تولید کند.
استفاده از مثالها مخصوصاً زمانی مفید است که میخواهید مدل به یک ساختار خاص یا قالب مشخص پایبند باشد و نتایج دقیقتری بدهد.
مثال پرامپت چند-شات:


برای هدایت نحوه تولید متن توسط مدلهای زبانی بزرگ (LLM) چند تکنیک پرکاربرد وجود دارد. هر کدام روی جنبهای خاص از تعامل با مدل تمرکز میکنند:
1. System Prompting
این روش وظیفه و هدف کلی مدل را مشخص میکند. به زبان ساده، به مدل میگویید «قراره چی کار کنی». مثلاً میتوانید به مدل بگویید متن را ترجمه کند یا نظرات را دستهبندی کند. این تکنیک یک دید کلی از وظیفه به مدل میدهد.
2. Contextual Prompting
در این تکنیک، جزئیات یا اطلاعات پسزمینه مرتبط با موضوع یا وظیفه ارائه میشود. این اطلاعات به مدل کمک میکند دقیقاً بفهمد چه چیزی از آن خواسته شده و پاسخ مناسب تولید کند.
3. Role Prompting
اینجا به مدل یک شخصیت یا هویت داده میشود تا مطابق با آن رفتار کند. مثلاً میتوانید بگویید «تو یک معلم هستی» یا «مثل یک دوست صحبت کن». این باعث میشود پاسخهای مدل با نقش و رفتار موردنظر شما همخوانی داشته باشد.
این سه تکنیک ممکن است همپوشانی داشته باشند. مثلاً وقتی مدلی نقش یک مترجم را میگیرد، میتواند همزمان اطلاعات زمینهای هم داشته باشد (مثل «این متن را از فارسی به انگلیسی ترجمه کن»). اما هر کدام هدف اصلی متفاوتی دارند.
پرامپت سیستمی به شما امکان میدهد رفتار کلی مدل را تنظیم کنید. میتوانید مشخص کنید مدل چه نوع دستیاری باشد، چگونه پاسخ دهد و چه محدودیتهایی داشته باشد.
برای مثال، در جدول زیر یک پرامپت سیستمی نشان داده شده که نحوه بازگرداندن خروجی توسط مدل را مشخص میکند.
دمای مدل (Temperature) برای افزایش خلاقیت بالاتر تنظیم شده است.
محدودیت توکن (Token Limit) هم بالا در نظر گرفته شده است.
با وجود این تنظیمات، به دلیل دستورالعمل واضح درباره فرمت خروجی، مدل دقیقاً مطابق انتظار عمل کرد و متن اضافه تولید نکرد.
میخواهید سریعتر و حرفهایتر پرامپت بنویسید؟ همین حالا سر بزنید به بخش قالبهای آماده پرامپت و با یک کلیک، بهترین ایدهها را برای استفاده در پروژههای هوش مصنوعی در اختیار بگیرید
مثال پرامپت سیستمی:

پرامپتهای سیستمی (System Prompts) میتوانند برای تولید خروجیهایی که نیازمندیهای خاصی دارند، بسیار مفید باشند.
علت نامگذاری «پرامپت سیستمی» این است که در واقع شما دارید یک وظیفه یا دستورالعمل اضافی به سیستم (هوش مصنوعی) میدهید (علاوه بر درخواست اصلیتان).
مثال:
میتوانید از پرامپت سیستمی استفاده کنید تا یک قطعه کد تولید شود که با یک زبان برنامهنویسی خاص سازگار باشد.
یا میتوانید خروجی را با ساختار مشخصی مانند JSON دریافت کنید.
برای نمونه، در جدول ۴ نشان داده شده که چگونه با استفاده از پرامپت سیستمی، خروجی دقیقاً در قالب JSON تولید شده است.

وقتی خروجی مدل را به شکل آبجکتهای JSON دریافت میکنید، چند مزیت مهم دارد:
عدم نیاز به ساخت دستی JSON:
در کاربردهای واقعی، لازم نیست بعد از دریافت پاسخ از مدل، JSON را به صورت دستی بسازید؛ مدل مستقیماً خروجی را با ساختار مشخص ارائه میدهد.
دریافت داده مرتبشده:
میتوانید دادهها را از ابتدا به شکل مرتبشده دریافت کنید. این ویژگی هنگام کار با دادههای تاریخ و زمان (datetime objects) بسیار کاربردی است، زیرا مرتبسازی این دادهها میتواند چالشبرانگیز باشد.
ساختارمند کردن و کاهش خطا:
درخواست خروجی با فرمت JSON مدل را مجبور میکند اطلاعات را دقیقاً در قالب کلیدها و مقادیر تعریفشده ارائه دهد. این کار باعث کاهش تولید اطلاعات نادرست یا توهمزایی (Hallucinations) توسط مدل میشود.
پرامپتهای سیستمی میتوانند برای کنترل ایمنی و جلوگیری از محتوای نامناسب یا سمی هم استفاده شوند. کافی است یک دستورالعمل اضافی به پرامپت اضافه کنید، مانند:
«شما باید در پاسخ خود محترمانه باشید.»
در پرامپت نقشدار، به مدل یک نقش مشخص داده میشود تا پاسخها تخصصیتر و متمرکزتر شوند.
مثالها:
«تو یک معلم هستی»
«تو یک ویراستار کتاب هستی»
«تو یک سخنران انگیزشی هستی»
وقتی نقش مدل مشخص شد، میتوانید درخواستهایی متناسب با آن نقش به مدل بدهید. برای مثال، یک مدل با نقش معلم میتواند یک طرح درس بنویسد که بعداً توسط شما بررسی شود.
در جدول ۵، نمونهای نشان داده شده که در آن مدل نقش راهنمای سفر را ایفا میکند.
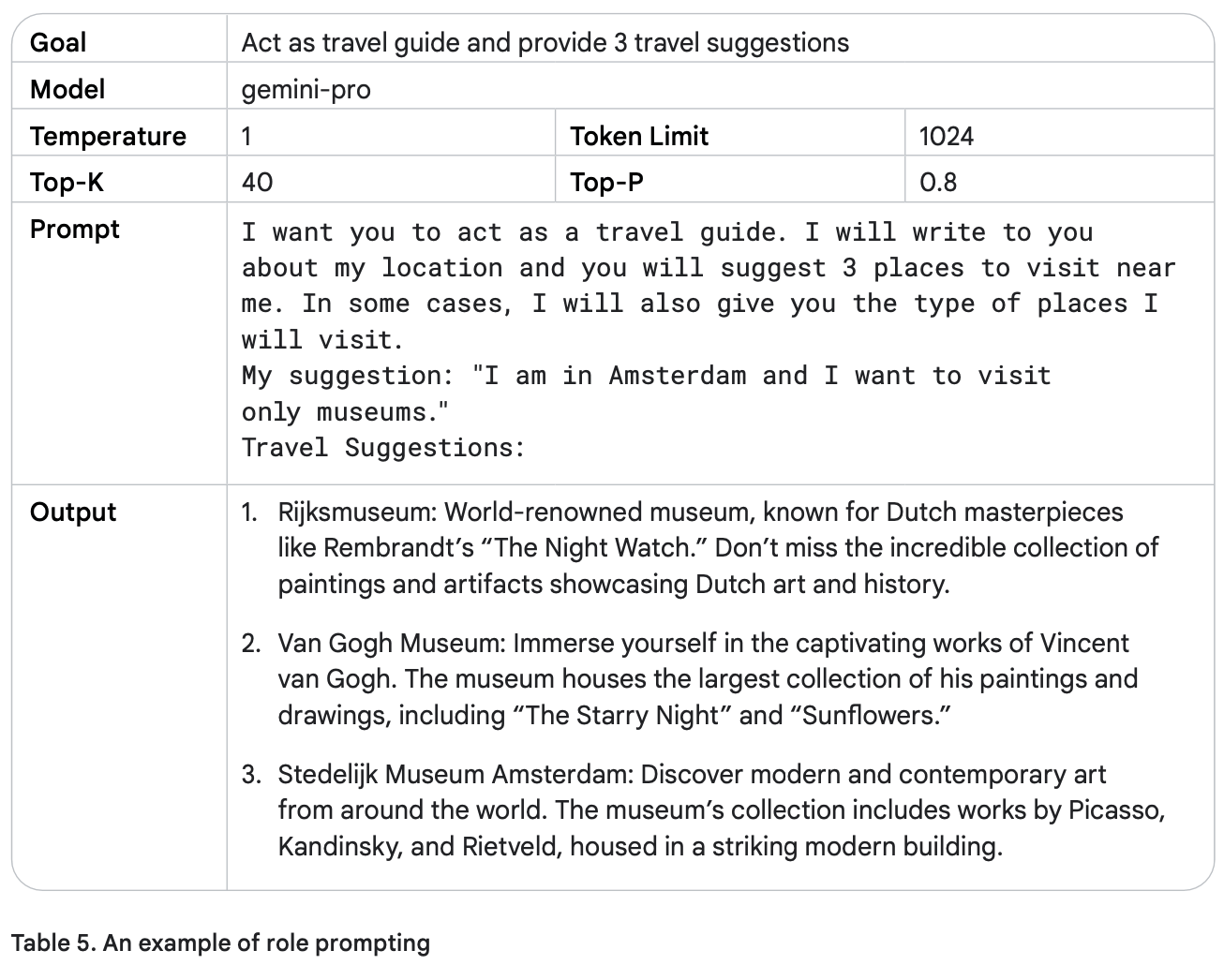
مثال بالا نشان میدهد که مدل هوش مصنوعی نقش یک کارمند آژانس مسافرتی را ایفا میکند. اگر همین نقش را به «معلم جغرافیا» تغییر دهید، پاسخ مدل کاملاً متفاوت خواهد بود.
تعریف یک دیدگاه نقشمحور برای مدل، مانند ارائه یک الگو (blueprint) است. این الگو مشخص میکند که چه لحن، سبک و سطح تخصصی از مدل انتظار دارید.
با این کار، کیفیت، مرتبط بودن و اثربخشی خروجی نهایی شما بهطور قابل توجهی افزایش مییابد.

چند سبک نوشتاری مؤثر وجود دارد که میتوانید در پرامپتهای خود استفاده کنید:
چالشی (Confrontational): کمی تند و مستقیم، برای به چالش کشیدن مخاطب.
توصیفی (Descriptive): با جزئیات زیاد و تصویرسازی.
مستقیم (Direct): بدون حاشیه و سر اصل مطلب.
رسمی (Formal): با ادبیات و ساختار رسمی.
طنزآمیز (Humorous): شوخطبعانه و با چاشنی خنده.
تأثیرگذار (Influential): برای اثرگذاری بر مخاطب.
غیررسمی (Informal): دوستانه و خودمانی.
الهامبخش (Inspirational): برای ایجاد انگیزه و امید.
متقاعدکننده (Persuasive): برای قانع کردن مخاطب.
حالا میتوانیم پرامپت خود را در جدول ۶ تغییر دهیم تا سبکی طنزآمیز و الهامبخش داشته باشد و خروجی جذابتر و انگیزشی تولید کند.

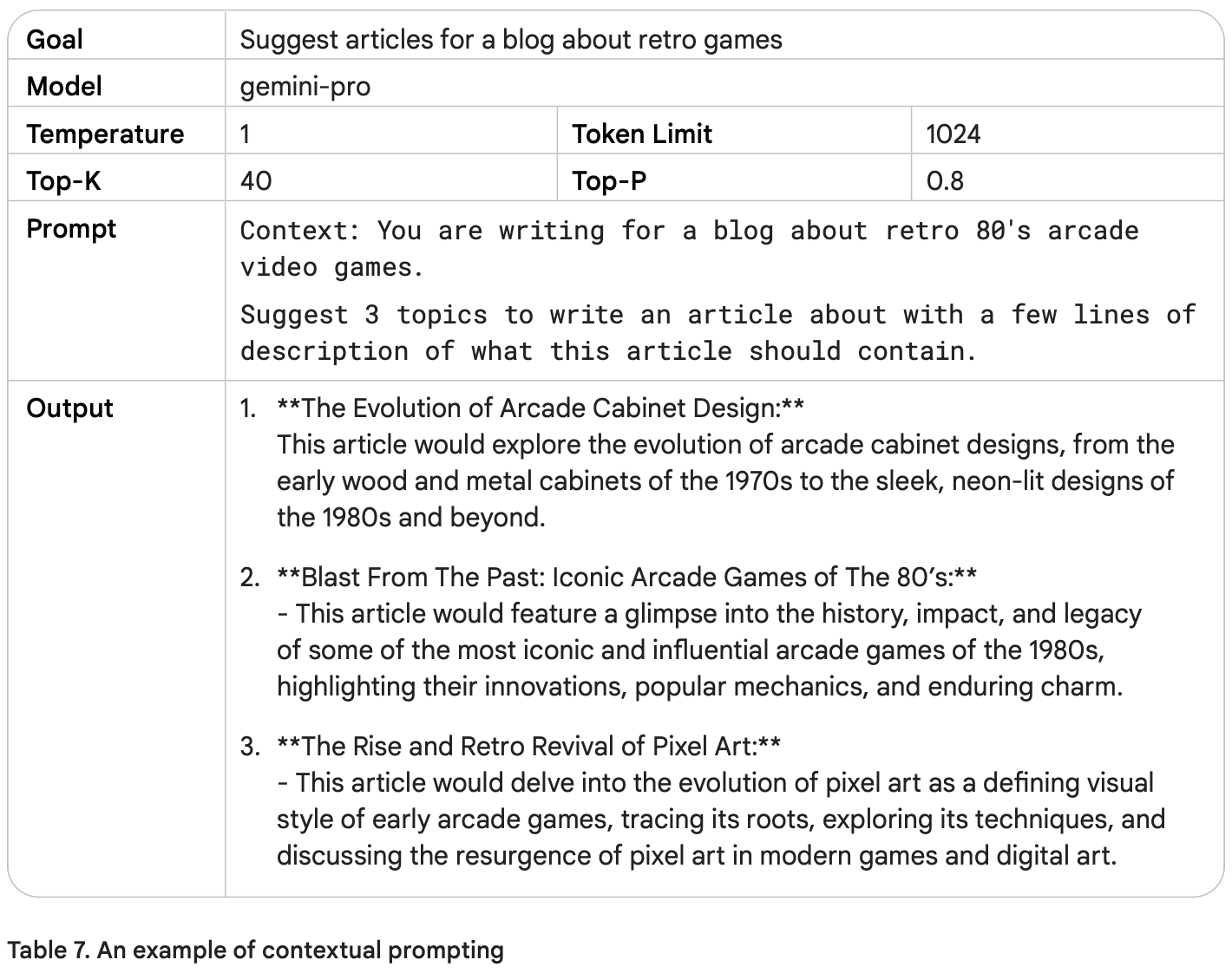
در پرامپت کانتکسچوال، به مدل اطلاعات زمینهای اضافی داده میشود تا پاسخهای دقیقتر و مرتبطتری ارائه کند.
این تکنیک مخصوصاً وقتی مفید است که مدل نیاز دارد زمینه یا پیشزمینهای درباره موضوع داشته باشد تا بتواند بهترین پاسخ را بدهد.
مثال پرامپت کانتکسچوال:
پرامپت استپبک یک تکنیک برای بهبود عملکرد مدلهای زبانی بزرگ (LLM) است. در این روش:
ابتدا به مدل یک سؤال کلی مرتبط با وظیفه داده میشود.
سپس پاسخ این سؤال کلی به عنوان ورودی برای درخواست بعدی که وظیفه خاص را انجام میدهد، استفاده میشود.
این «گام به عقب» به مدل کمک میکند تا دانش زمینهای و فرآیندهای استدلالی خود را فعال کند قبل از اینکه به مسئله خاص بپردازد.
با در نظر گرفتن اصول کلی، مدل میتواند پاسخهای دقیقتر و عمیقتر تولید کند. پرامپت استپبک مدل را تشویق میکند که انتقادی فکر کند و دانش خود را به روشهای خلاقانه به کار ببرد.
مزیت دیگر این روش، کاهش سوگیریها است؛ چون مدل به جای تمرکز روی جزئیات کوچک، روی اصول کلی مسئله تمرکز میکند.
مثالها:
برای فهم بهتر نحوه عملکرد پرامپت استپبک، ابتدا یک درخواست سنتی (جدول ۸) را بررسی میکنیم و سپس آن را با یک درخواست استپبک (جدول ۹) مقایسه میکنیم.
مثال پرامپت استپبک:

وقتی دمای مدل (Temperature) را روی ۱ تنظیم میکنید، ممکن است متنهای خلاقانه و جالب برای یک خط داستانی کلی تولید شود، اما این نوشتهها معمولاً تصادفی و کلی خواهند بود و جزئیات دقیق یا منسجمی ندارند.

این تنظیمات و تکنیکها به نظر برای یک بازی ویدیویی اولشخص مناسب هستند. حالا بیایید به درخواست قبلی برگردیم، ولی این بار پاسخ سوال استپبک را به عنوان زمینه (Context) به مدل بدهیم و ببینیم چه پاسخی تولید میکند.
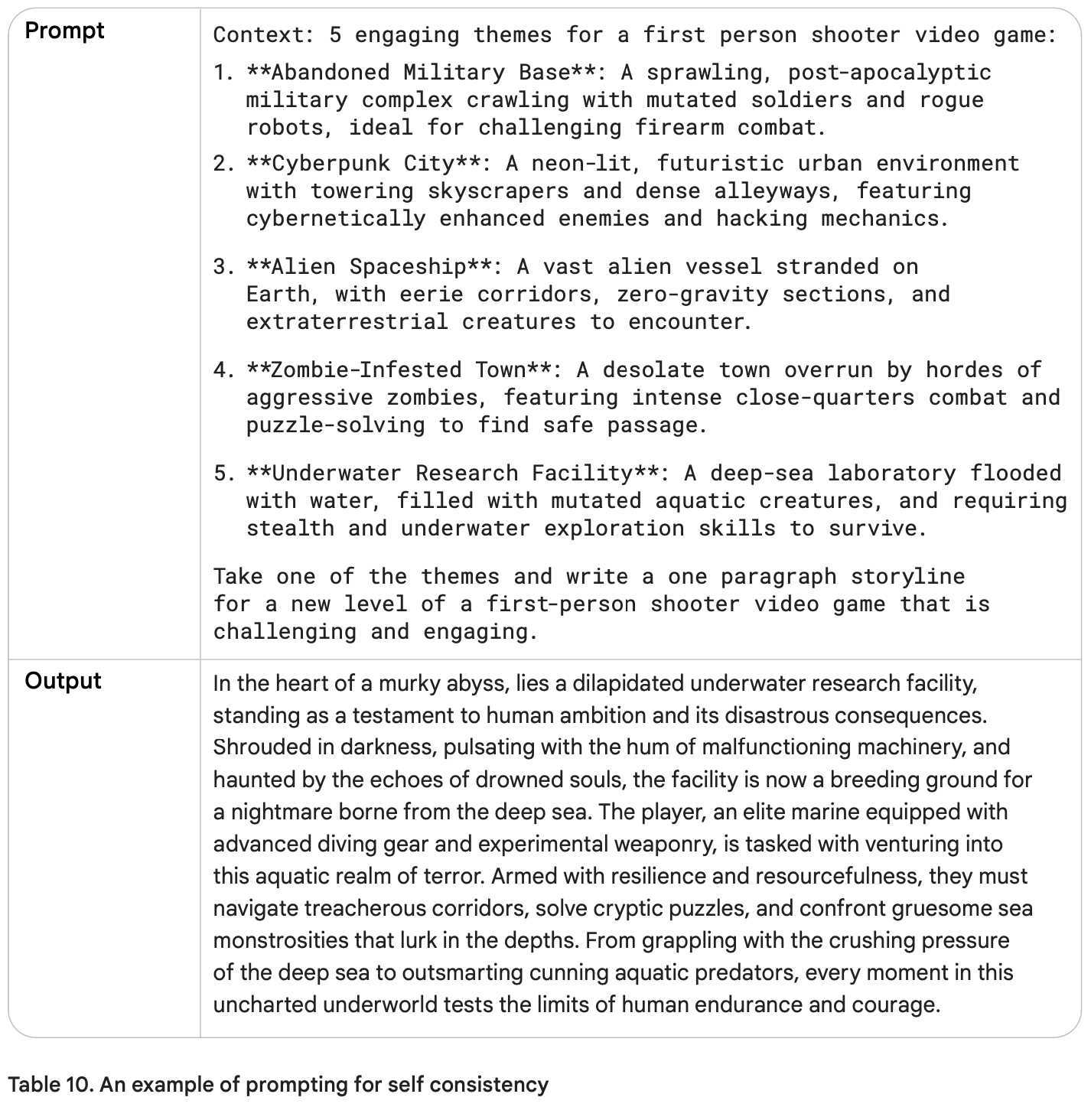
این شبیه یک بازی ویدیویی جالب به نظر میرسد! با استفاده از تکنیکهای Step-Back Prompting میتوانید دقت درخواستهای خود را به طور قابل توجهی افزایش دهید.
زنجیره تفکر (CoT) یک تکنیک است که توانایی استدلال مدلهای زبانی بزرگ (LLM) را با تولید گامهای استدلالی میانی بهبود میبخشد. این روش به مدل کمک میکند تا پاسخهای دقیقتر و منطقیتر ارائه کند.
میتوانید CoT را با پرامپت Few-Shot ترکیب کنید تا در وظایف پیچیده که نیاز به استدلال قبل از پاسخ دارند، نتایج بهتری بگیرید.
مزایای CoT:
تلاش کم، تأثیر زیاد: نیازی به تنظیم دقیق مدل (Finetuning) ندارد و با مدلهای آماده (Off-the-Shelf LLMs) به خوبی کار میکند.
شفافیت و تفسیرپذیری: میتوانید گامهای استدلالی مدل را ببینید و در صورت بروز مشکل، آن را پیدا کنید.
پایداری بین نسخهها: درخواستهایی که از CoT استفاده میکنند، نسبت به درخواستهای بدون استدلال، عملکرد پایدارتری بین نسخههای مختلف مدلها دارند.
معایب CoT:
پاسخ مدل شامل گامهای استدلالی میشود، بنابراین تعداد توکنهای خروجی بیشتر است.
این موضوع باعث میشود هزینه پردازش بالاتر و زمان تولید پاسخ طولانیتر شود.
مثال:
برای درک بهتر، ابتدا یک درخواست بدون CoT (جدول ۱۱) مینویسیم تا نقاط ضعف مدلهای زبانی بزرگ را نشان دهیم و سپس مثال زنجیره تفکر را بررسی میکنیم.
مثال زنجیره تفکر:
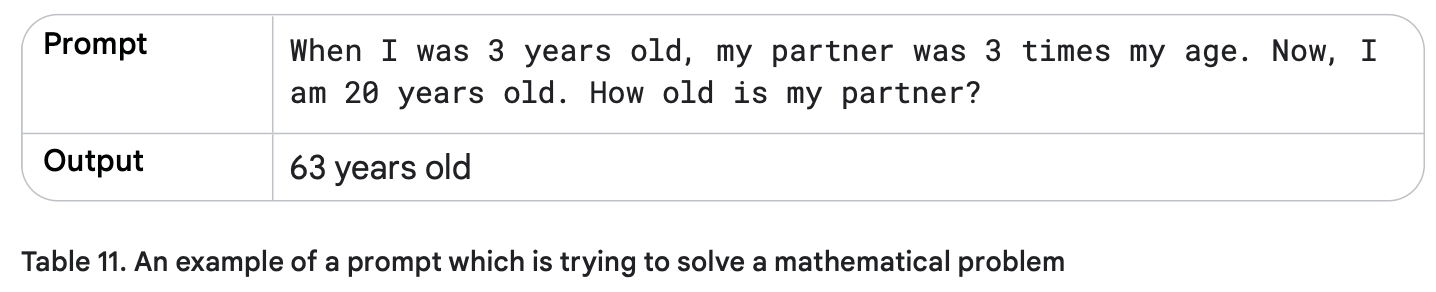
خوب، این پاسخ کاملاً اشتباه است! واقعیت این است که مدلهای زبانی بزرگ (LLM) اغلب در کارهای ریاضی دچار مشکل میشوند و حتی برای یک عملیات ساده مثل ضرب دو عدد، ممکن است جواب اشتباه بدهند.
علت این است که این مدلها روی حجم زیادی از متن آموزش دیدهاند و ریاضیات نیاز به روش متفاوتی دارد.
حالا بیایید بررسی کنیم که اگر از گامهای استدلالی میانی (Chain of Thought) استفاده کنیم، آیا خروجی دقیقتر و درستتر خواهد شد یا نه.
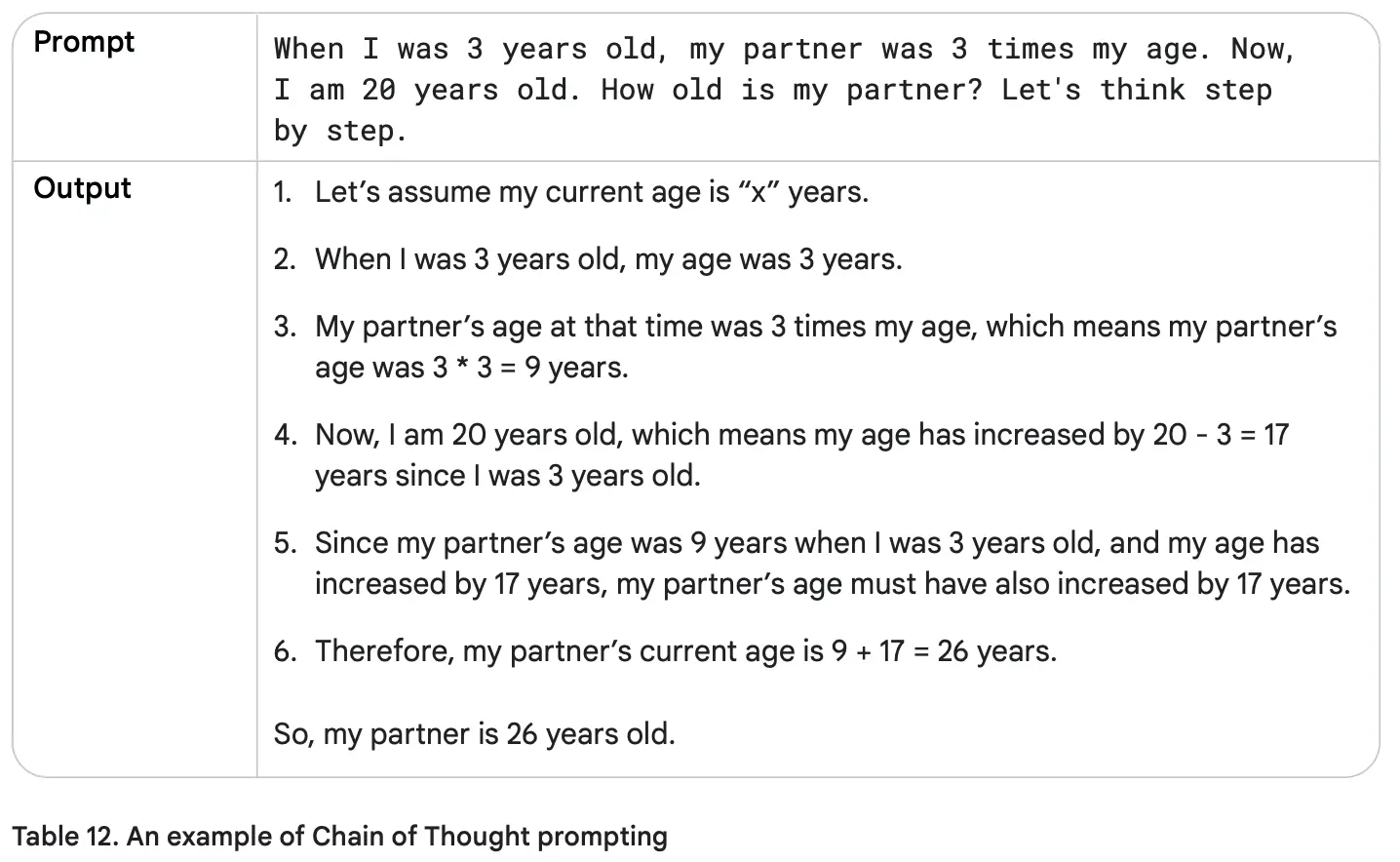
خوبه، حالا پاسخ نهایی درست شد! دلیلش این است که ما به مدل دستور واضح دادیم که هر گام را توضیح دهد، به جای اینکه فقط جواب نهایی بدهد. جالب است که مدل ۱۷ سال افزایش را به درستی جمع کرد.
اگر من بودم، برای حل چنین مسئلهای ابتدا فاصله سالها بین خودم و پارتنرم را حساب میکردم و بعد جمع میکردم، مثلاً: (20 + (9 - 3)). بیایید به مدل کمک کنیم تا شبیه من فکر کند!
جدول ۱۲: نمونهای از زنجیره تفکر بدون نمونه (Zero-Shot CoT)
جدول ۱۳: وقتی زنجیره تفکر با تکنمونه (Single-Shot) یا چندنمونه (Few-Shot) ترکیب میشود، قدرت مدل بسیار افزایش مییابد و نتایج دقیقتری ارائه میکند.

زنجیره تفکر برای کارهای مختلفی مفید است، مثل:
تولید کد (Code Generation):
میتوانید درخواست را به چند گام تقسیم کنید و هر گام را به بخش مشخصی از کد مرتبط کنید.
ایجاد داده مصنوعی (Synthetic Data):
برای مثال، وقتی یک نقطه شروع دارید، مثل «محصول اسمش XYZ است، یک توضیح بنویس و مدل را بر اساس فرضیات خود هدایت کن».
به طور کلی، هر کاری که بتوان با توضیح دادن و گفتوگو حل کرد، گزینه مناسبی برای زنجیره تفکر است. هرچه گامهای حل مسئله را واضحتر بیان کنید، نتیجه بهتر خواهد بود.
اگر نمیخواهید وقت زیادی برای نوشتن پرامپت بگذارید، ما مجموعهای از قالبهای آماده پرامپت را برایتان آماده کردهایم. کافیست انتخاب کنید و بلافاصله استفاده کنید
خودسازگاری یک تکنیک پیشرفته است که در آن از مدل خواسته میشود چندین مسیر استدلالی برای یک مسئله تولید کند و سپس پاسخی که بیشترین سازگاری را دارد انتخاب کند.
گرچه مدلهای زبانی بزرگ در کارهای پردازش زبان طبیعی موفق هستند، توانایی آنها در استدلال هنوز محدود است و فقط با بزرگتر کردن مدل حل نمیشود. همانطور که در بخش زنجیره تفکر دیدیم، میتوان به مدل دستور داد گامهای استدلالی تولید کند. اما CoT معمولاً از رمزگشایی حریصانه (Greedy Decoding) استفاده میکند که تأثیر آن محدود است.
روش خودسازگاری مسیرهای استدلالی متنوع تولید میکند و با ترکیب نمونهبرداری (Sampling) و رأیگیری اکثریت (Majority Voting)، پاسخی که بیشترین سازگاری را دارد انتخاب میکند. این روش دقت و انسجام پاسخها را افزایش میدهد، اما هزینههای محاسباتی بالاتری دارد.
تولید مسیرهای استدلالی متنوع:
همان درخواست چندین بار به مدل داده میشود. با تنظیم دمای بالا (High Temperature)، مدل مسیرها و دیدگاههای متفاوتی تولید میکند.
استخراج پاسخ از هر خروجی:
از هر پاسخ تولیدشده، جواب نهایی جدا میشود.
انتخاب شایعترین پاسخ:
پاسخی که بیشترین تکرار را دارد، به عنوان جواب نهایی انتخاب میشود.
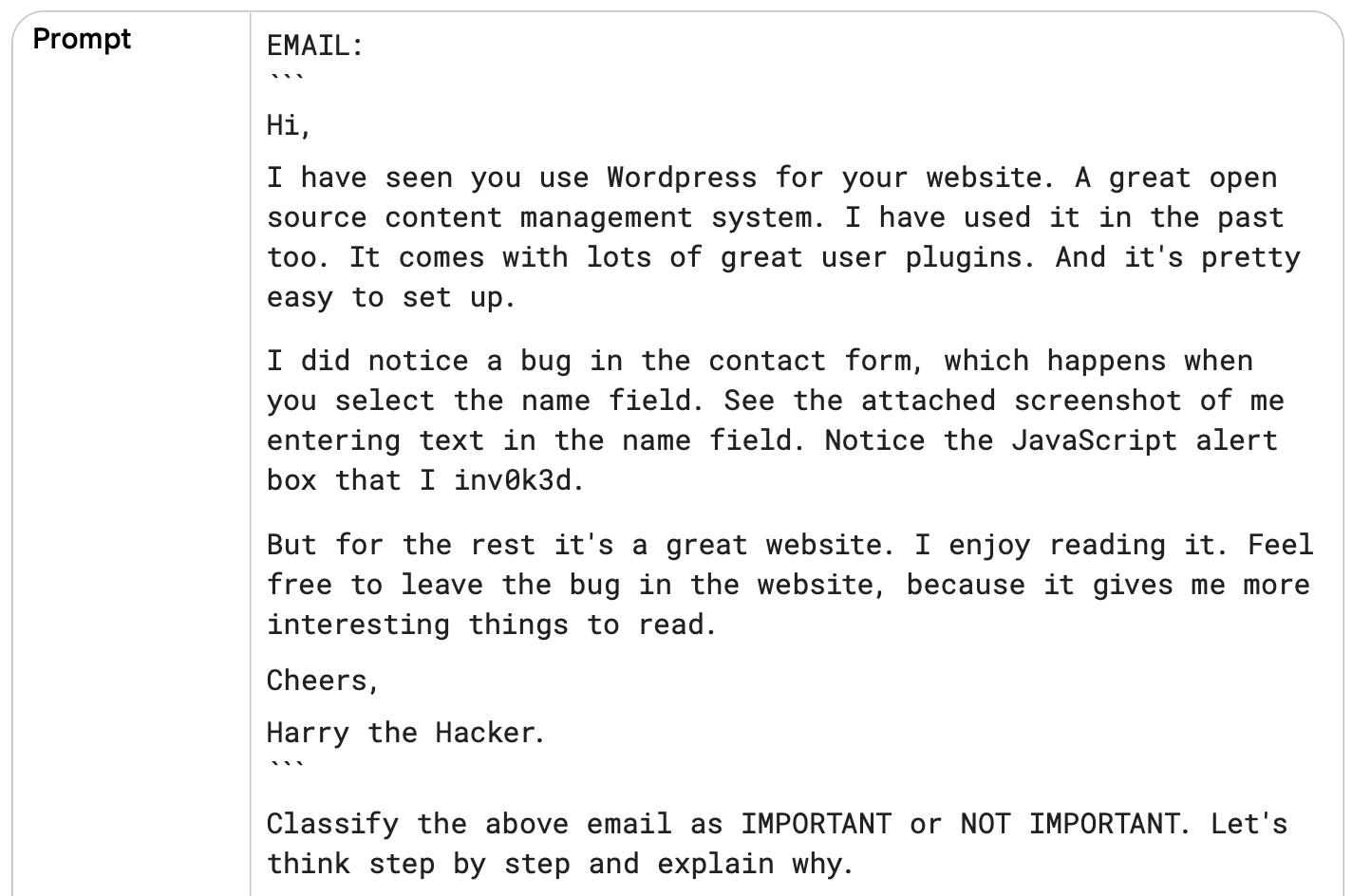
فرض کنید یک سیستم ایمیل داریم که ایمیلها را به دو دسته مهم (IMPORTANT) یا غیرمهم (NOT IMPORTANT) تقسیم میکند.
یک درخواست زنجیره تفکر بدون نمونه (Zero-Shot CoT) چندین بار به مدل فرستاده میشود تا ببینیم آیا پاسخها بعد از هر بار ارسال متفاوت هستند یا نه.
در این مثال به لحن دوستانه، انتخاب کلمات و حتی کنایه (Sarcasm) در متن ایمیل توجه میکنیم، زیرا همه اینها ممکن است مدل را گمراه کنند.
مثال خودسازگاری:


درخت تفکرات (ToT) یک توسعه از زنجیره تفکر است که به مدل اجازه میدهد چندین مسیر استدلالی را همزمان کاوش کند و مسیرهای غیرمفید یا غیرامیدوارکننده را حذف (هرس) کند.
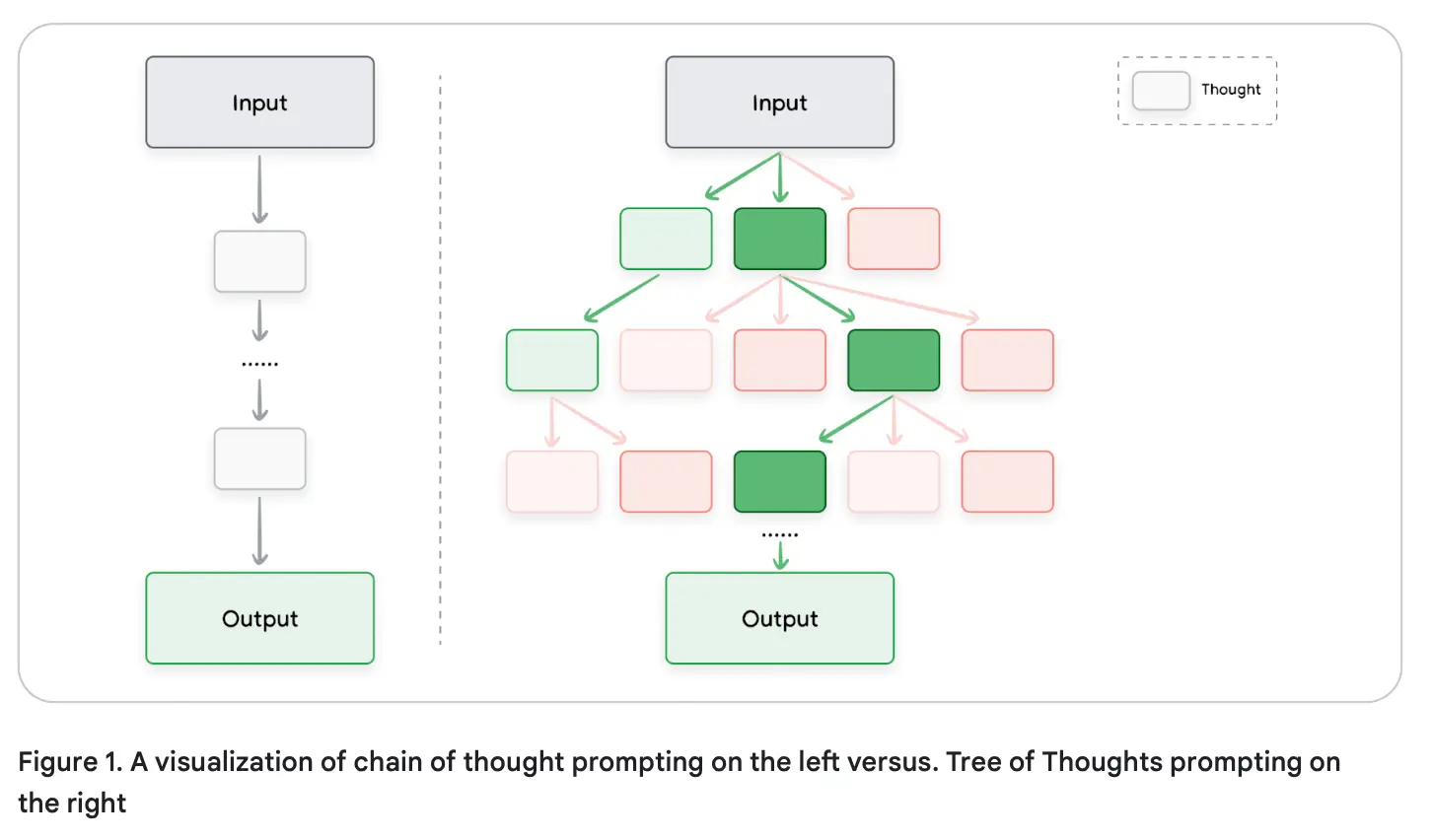
حالا که با روشهای زنجیره تفکر (Chain of Thought – CoT) و خودسازگاری (Self-Consistency) آشنا شدیم، بیایید نگاهی به درخت افکار (Tree of Thoughts – ToT) بیندازیم.
این روش در واقع CoT را تعمیم میدهد، زیرا به مدلهای زبانی بزرگ اجازه میدهد مسیرهای مختلف و متعدد استدلالی را به طور همزمان بررسی کنند، به جای اینکه فقط یک زنجیره خطی و واحد را دنبال کنند.
این مفهوم در شکل ۱ نمایش داده شده است.
این رویکرد باعث میشود ToT بهویژه برای وظایف پیچیده و نیازمند کاوش (Exploration) بسیار مناسب باشد.
سازوکار آن مبتنی بر نگهداری یک درخت از افکار است، که در آن هر «فکر» (Thought) نمایانگر یک دنباله زبانی منسجم و گام میانی در حل مسئله است. سپس مدل میتواند با انشعاب گرفتن (Branching) از گرههای مختلف، مسیرهای استدلالی متعدد را بررسی کند و بهترین مسیرها را انتخاب کند.
پرامپت نویسی ReAct یک پارادایم جدید در مدلهای زبانی بزرگ (LLM) است که به آنها کمک میکند وظایف پیچیده را با ترکیب استدلال به زبان طبیعی و ابزارهای خارجی (مثل جستجو، مفسر کد و غیره) حل کنند.
این روش به مدل اجازه میدهد تا کارهایی مثل تعامل با APIها برای دریافت اطلاعات را انجام دهد، که گامی اولیه به سمت مدلسازی ایجنت (Agent Modeling) محسوب میشود.
در ReAct، مدل مانند انسانها عمل میکند: ابتدا استدلال میکند و سپس برای بهدست آوردن اطلاعات، اقدام میکند.
نحوه کار ReAct:
مدل درباره مسئله استدلال میکند و یک طرح عملی تولید میکند.
اقدامات موجود در طرح اجرا میشوند و نتایج مشاهده میشوند.
مدل از این مشاهدات برای بهروزرسانی استدلال خود استفاده میکند و طرح عملی جدیدی میسازد.
این حلقه فکر–عمل (thought–action) ادامه پیدا میکند تا مدل به راهحل برسد.
برای مشاهده این روش، باید کدی بنویسید.
در قطعه کد شماره ۱، از فریمورک LangChain در پایتون استفاده شده، به همراه VertexAI و بسته google-search-results.
برای اجرای نمونه، نیاز به کلید SerpAPI رایگان دارید که میتوانید از این لینک بسازید و متغیر محیطی SERPAPI_API_KEY را تنظیم کنید.
مثال واکنش:
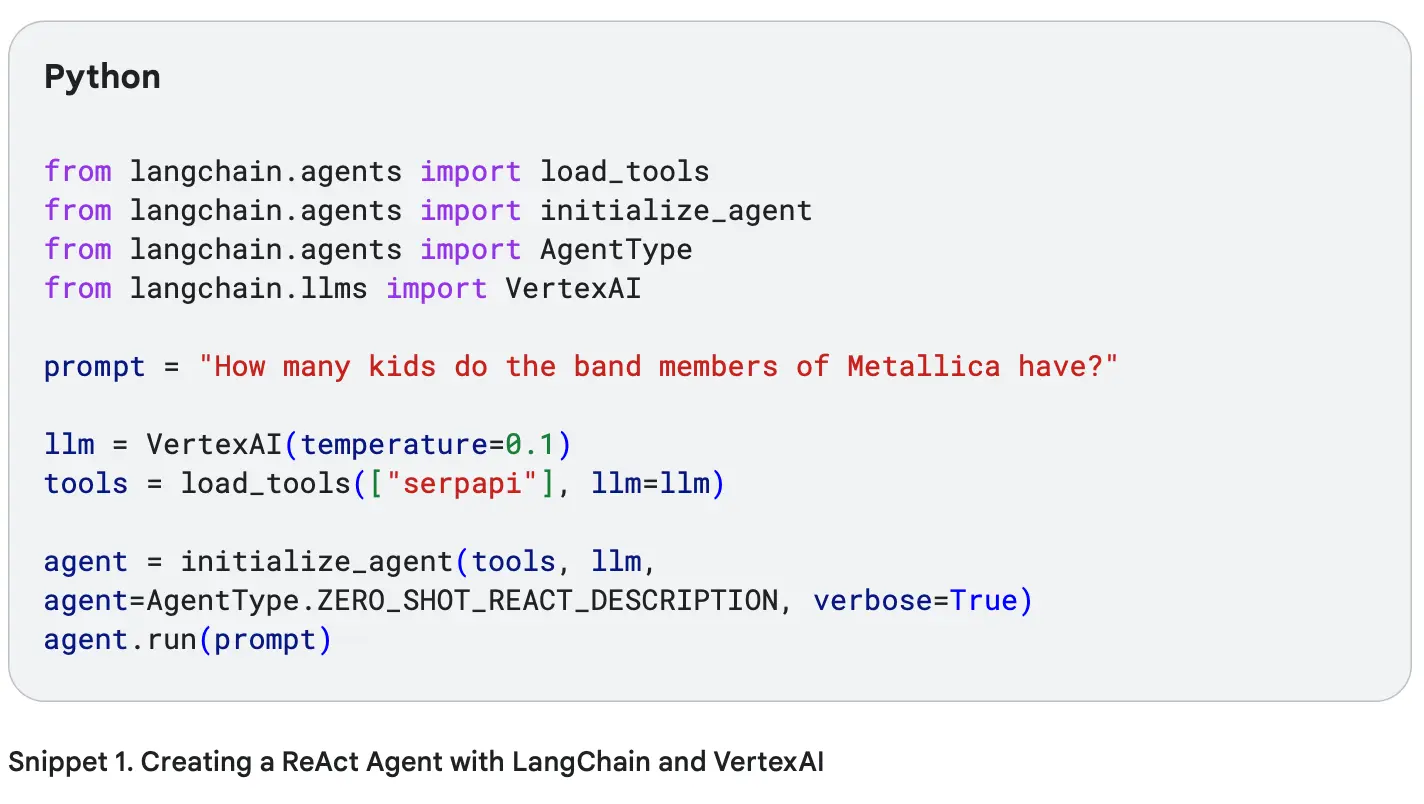
حالا بیایم یه کد پایتون بنویسیم که وظیفهای برای مدل زبانی بزرگ (LLM) تعریف کنه: اعضای گروه متالیکا چندتا بچه دارند؟

ت
این کد نتیجه نهایی را نشان میدهد و از روش ReAct استفاده میکند.
در واقع، مدل زبانی یک زنجیره از پنج جستجو انجام میدهد.
مدل ابتدا نتایج جستجوی گوگل را بررسی میکند تا اسامی اعضای گروه متالیکا را پیدا کند.
سپس این نتایج را به عنوان مشاهدات ذخیره کرده و استدلالش را برای جستجوی بعدی ادامه میدهد.
مدل متوجه میشود که گروه متالیکا چهار عضو دارد و سپس برای هر عضو، تعداد بچهها را پیدا کرده و در نهایت همه را جمع میزند.
پاسخ نهایی تعداد کل بچهها است.
مدلهای زبانی بزرگ (LLM) میتوانند در نوشتن، توضیح، ترجمه و اشکالزدایی کد کمک کنند.
مدل Gemini عمدتاً روی درخواستهای متنی تمرکز دارد و این شامل نوشتن درخواست برای تولید کد هم میشود.
هنگام درخواست از LLM برای نوشتن کد، دستورالعمل واضح و زبان برنامهنویسی مورد نظر را مشخص کنید.
Gemini میتواند نقش یک برنامهنویس را ایفا کند و به شما کمک کند تا با هر زبان برنامهنویسی دلخواهتان کد بنویسید. این کار باعث میشود فرآیند کدنویسی سریعتر شود.
فرض کنید یک پوشه دارید که صدها فایل داخل آن نیاز به تغییر نام دارند.
تغییر نام تکتک فایلها زمانبر است.
شاید کمی دستورات Bash بلد باشید و بتوانید یک اسکریپت خودکارسازی بنویسید، اما نوشتن آن هم زمان میبرد.
راهحل: یک پرامپت برای هوش مصنوعی بنویسید که این کار را برای شما انجام دهد.
این پرامپت را میتوانید در چتبات عمومی Gemini وارد کنید.
یا اگر میخواهید اطلاعاتتان محرمانه بماند، میتوانید پرامپتها را داخل حساب Google Cloud و با Vertex AI Studio اجرا کنید.
مزیت Vertex AI Studio:
کنترل بیشتر روی تنظیمات مدل، مثل دمای مدل (Temperature) که روی خلاقیت و تنوع پاسخها تأثیر میگذارد.
امکان اجرای پرامپتها در محیط امن و خصوصی بدون انتشار عمومی دادهها.

کد نوشته شده Documentation دارد و توضیح داده که چه کاری انجام میدهد. اما باید بدانید که مدلهای هوش مصنوعی (LLMها) توانایی واقعی فکر کردن یا استدلال ندارند و ممکن است صرفاً دادههایی که آموزش دیدهاند را تکرار کنند.
بنابراین، حتماً قبل از استفاده، کد را خودتان بخوانید و تست کنید.
حالا بیایید امتحان کنیم که کد واقعاً کار میکند یا نه.
هدف: تغییر نام فایلها از filename.txt به draft_filename.txt در یک پوشه آزمایشی.
کد موجود در جدول ۱۶ را کپی کنید (فقط خود کد، بدون بلاکهای bash) و آن را در یک فایل جدید به نام rename_files.sh ذخیره کنید.
یک پنجره ترمینال باز کنید و دستور زیر را اجرا کنید:
پس از اجرای دستور، از شما اسم پوشه پرسیده میشود. مثلاً اگر پوشه آزمایشی شما test است، آن را وارد کرده و Enter بزنید.
اسکریپت بدون مشکل اجرا میشود.
پیام زیر را مشاهده خواهید کرد:
اگر داخل پوشه آزمایشی (test) را بررسی کنید، نام همه فایلها به درستی به draft_filename.txt تغییر کرده است.
✅ جواب داد! کد کار کرد.
یک مثال دیگه برای وظایف پیچیدهتر، میتوانید جزئیات بیشتری ارائه دهید:
Create a Python class for a Bank Account with the following features: 1. Initialize with account holder name and starting balance 2. Methods for deposit and withdrawal 3. A method to calculate interest (assume 2% annual interest) 4. Error handling for insufficient funds 5. A method to display the current balance and account details Use proper documentation and follow PEP 8 style guidelines.
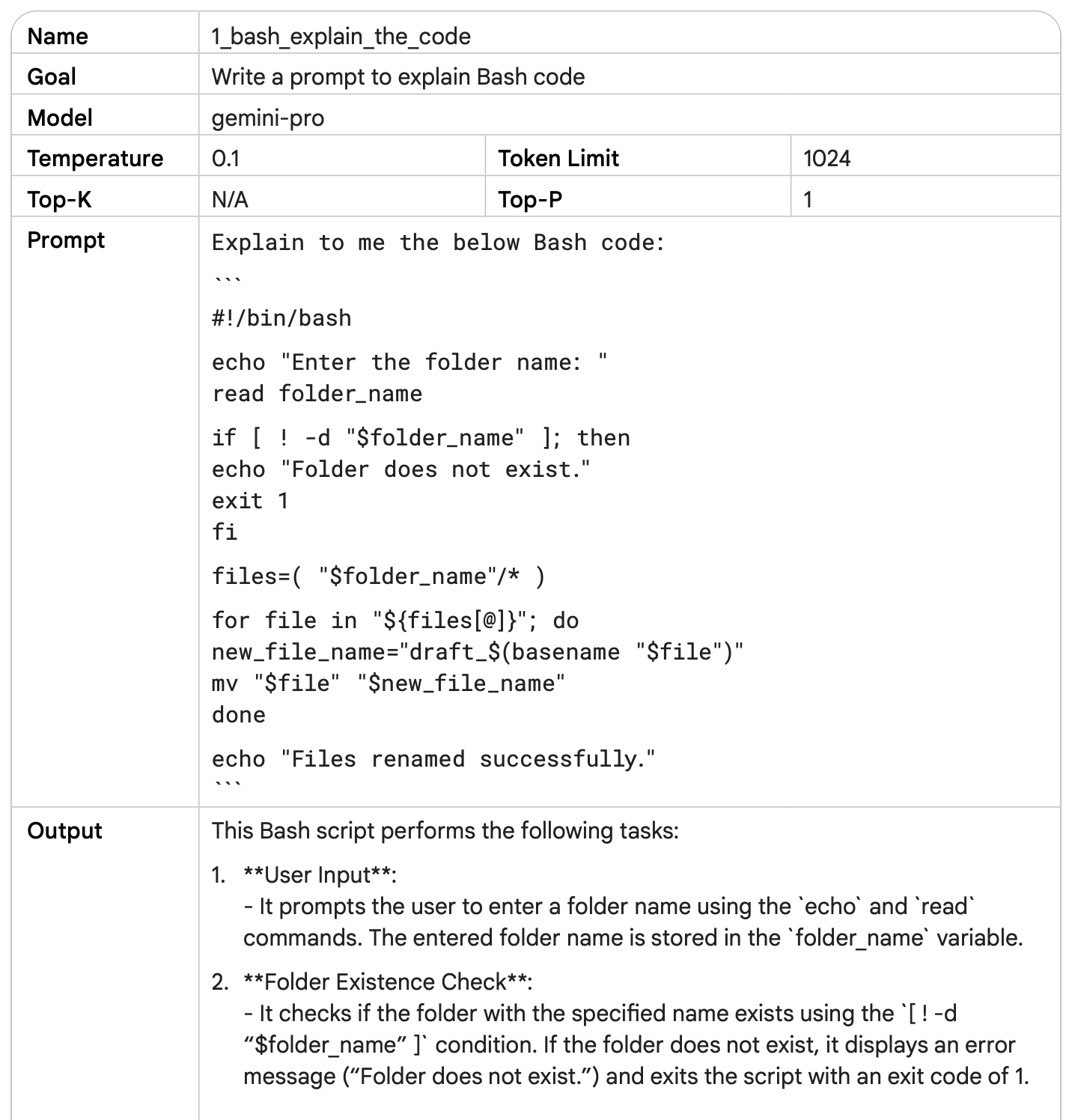

مدلهای زبان بزرگ (LLMها) میتونن کد رو از یک زبان برنامهنویسی به زبان دیگه ترجمه کنن.
مثلاً کد Bash که در جدول ۱۶ دیدیم، عملکرد خوبی داره، اما یه محدودیت داره:
این اسکریپت نام فایلها رو از کاربر نمیپرسه و همه چیز از قبل ثابت تعریف شده.
اگه امکان دریافت ورودی از کاربر رو داشت، خیلی کاربردیتر و قابل استفاده مجددتر میشد.
ایدهآل اینه که این قابلیت به صورت یه برنامه جداگانه با رابط کاربری (UI) پیادهسازی بشه تا کاربر راحتتر بتونه ازش استفاده کنه.
برای ساخت چنین برنامهای، مخصوصاً اپلیکیشنهای وب، پایتون نسبت به Bash مناسبتره.
خبر خوب: LLMها میتونن کمک کنن کد Bash رو به پایتون تبدیل کنید و نسخهای تعاملیتر و قابل توسعه بسازید.
نمونهای از این کار را در جدول ۱۸ ببینید:
![]()
![]()
کد خروجی پرامپت رو کپی کنید و در یک فایل جدید به نام file_renamer.py ذخیره کنید.
برای اجرای کد، یه پنجره ترمینال باز کنید و دستور زیر رو اجرا کنید:
وقتی از Language Studio برای گرفتن کد (خصوصاً پایتون) استفاده میکنید، حتماً روی دکمه ‘Markdown’ کلیک کنید.
چرا؟ چون در غیر این صورت کد به صورت متن ساده (plain text) میاد و تورفتگیها (indentation) که برای پایتون حیاتی هستن، درست نمایش داده نمیشن.
پایتون برای تشخیص بلوکهای کد از تورفتگی استفاده میکنه، پس این مرحله خیلی مهمه.
مدلهای LLM میتونن در شناسایی و رفع خطاهای کد کمک کنند.
حالا بیایید به صورت دستی کد جدول ۱۸ رو کمی ویرایش کنیم:
کد باید نام پیشوند فایل (filename prefix) رو از کاربر دریافت کنه.
سپس این پیشوند رو به حروف بزرگ (Upper Case) تبدیل کنه.
نمونه کد ویرایش شده در قطعه کد ۳ (Snippet 3) موجوده، اما…
⚠️ بعضی خطاهای پایتون ممکنه ظاهر بشه! یعنی وقتی اجراش میکنید، کد ممکنه مشکل بده.
مثال پرامپت نویسی برای اشکالزدایی کد:

بنظر میاد باگ داره، بریم از LLM کمک بگیریم که کد رو Review و دیباگ کنه:




مدل نه تنها به شما نشان داد مشکل کد کجاست، بلکه باگهای دیگر کد را هم پیدا کرد و راهحل آنها را ارائه داد.
علاوه بر رفع خطاها، مدل پیشنهادهایی برای بهبود کلی کد هم داد، مثل روشهایی که کد را بهتر و کارآمدتر کند.
تا الان برای درخواست کد، ما از مدلهای زبانی بزرگ مبتنی بر متن استفاده میکردیم.
اما پرامپت چندوجهی یک مفهوم متفاوت است:
این روش اجازه میدهد مدل از چند نوع ورودی مختلف استفاده کند، نه فقط متن.
انواع ورودیها میتوانند شامل موارد زیر باشند:
متن
تصویر (عکس)
صدا (فایل صوتی)
کد
یا فرمتهای دیگر
ترکیب این ورودیها بستگی به تواناییهای مدل و کاری دارد که میخواهید انجام دهید.
ارائه مثالها
استفاده از تک-شات و چند-شات برای آموزش مدل بسیار مؤثر است.
مثالهای واضح کمک میکنند مدل الگوها را بهتر درک کند و پاسخهای دقیقتری بدهد.
مثالها مثل ابزار آموزشی برای مدل عمل میکنند.
وظایف پیچیده
برای وظایف دشوار، از چند-شات با مثالهای متنوع استفاده کنید تا مدل بهتر یاد بگیرد.
Translate the following English phrases to French: English: Hello, how are you? French: Bonjour, comment allez-vous? English: I would like to order a coffee, please. French: Je voudrais commander un café, s'il vous plaît. English: Where is the nearest train station? French:
ساده و مستقیم بنویسید: پرامپتهایی که واضح و کوتاه هستند، معمولاً بهترین نتیجه را میدهند.
از زبان پیچیده و مبهم پرهیز کنید: اگر خودتان هم متوجه پرامپت نمیشوید، مدل هم قادر به درک آن نخواهد بود.
در نوشتن پرامپت از افعال شبیه زیر میتوانید استفاده کنید:
Act, Analyze, Categorize, Classify, Contrast, Compare, Create, Describe, Define, Evaluate, Extract, Find, Generate, Identify, List, Measure, Organize, Parse, Pick, Predict, Provide, Rank, Recommend, Return, Retrieve, Rewrite, Select, Show, Sort, Summarize, Translate, Write.
به وضوح بگویید چه خروجی میخواهید: مدل بهتر عمل میکند وقتی دقیقاً میدانید چه پاسخی نیاز دارید.
دستورهای کوتاه و کلی کافی نیستند: پرامپتهای خیلی ساده ممکن است مدل را به خوبی راهنمایی نکنند و پاسخهای مبهم بدهند.

در پرامپت نویسی، برای هدایت پاسخ مدلهای زبانی بزرگ (LLM)، دو ابزار داریم: دستورات و محدودیتها. بیایید ببینیم تفاوتشان چیست و چرا بهتر است روی دستورات تمرکز کنیم.
اگر دنبال ابزارهای متنوع و کاربردی هوش مصنوعی هستید، ما در یک صفحه همه آنها را بهصورت دستهبندیشده جمعآوری کردهایم. همین حالا ببینید
دستورات به مدل میگویند چه کاری انجام دهد و خروجی چه شکل و سبکی داشته باشد.
مثال:
«پاسخ را به صورت یک پاراگراف کوتاه بنویس.»
این کمک میکند مدل دقیقاً بفهمد چه انتظاری از آن داریم.
محدودیتها به مدل میگویند چه کاری انجام ندهد یا از چه چیزی دوری کند.
مثال:
«از کلمات پیچیده و فنی استفاده نکن.»
اینها مانند خطوط قرمز هستند که پاسخ مدل باید در آنها بماند.
به مدل میگویند نتیجه مورد انتظار چیست
خلاقیت بیشتری در چارچوب مشخص ایجاد میکنند
سردرگمی مدل را کاهش میدهند
ممکن است باعث سردرگمی مدل شوند
خلاقیت را محدود میکنند
گاهی بین محدودیتها تناقض ایجاد میشود
برای جلوگیری از تولید محتوای مضر یا اشتباه
وقتی به قالب یا سبک خاصی نیاز داریم (مثلاً تعداد کلمات محدود)
به جای گفتن «چه کاری انجام نده»، بگویید «چه کاری انجام بده».
مثال: به جای «مبهم نباش»، بگویید «جزئیات واضح و مشخص بده».
اول با دستورات مثبت شروع کنید
در صورت نیاز از محدودیتها استفاده کنید
ترکیبهای مختلف را آزمایش کنید
نتایج را مستندسازی کنید

برای کنترل طول پاسخ، محدودیتهای خاصی را مشخص کنید.
مثال:

برای اینکه پرامپتها دوباره قابل استفاده و پویا باشند، میتوان از متغیرها استفاده کرد. متغیرها میتوانند مقادیر مختلفی بگیرند و پرامپت را برای ورودیهای متفاوت مناسب کنند.
به جای نوشتن نام یک شهر به صورت ثابت در پرامپت، میتوانید از یک متغیر استفاده کنید:
هر بار که پرامپت اجرا شود، میتوانید مقدار متغیر {city} را تغییر دهید و پاسخ متناسب با آن دریافت کنید.
جلوگیری از تکرار نوشتن متن مشابه
صرفهجویی در زمان و تلاش
سادهتر کردن استفاده از پرامپتها در برنامهها و سیستمهای بزرگ
اگر همان اطلاعات در چند پرامپت استفاده میشوند، میتوانید آنها را یک بار در متغیر ذخیره کنید و در پرامپتهای مختلف به آن ارجاع دهید. این کار مدیریت و نگهداری پرامپتها را بسیار آسان میکند.

برای گرفتن بهترین نتیجه از مدلهای زبانی بزرگ (LLM)، مهم است که فرمت پرامپت و سبک نوشتاری را آزمایش کنید.
سبک نوشتن: رسمی، دوستانه، ساده، طنزآمیز و …
انتخاب کلمات: استفاده از مترادفها یا عبارات مختلف
نوع پرامپت: سوالی، خبری، دستوری
سوالی
What was the Sega Dreamcast and why was it such a revolutionary console?سگا دریمکست چه بود و چرا یک کنسول انقلابی محسوب میشد؟
خبری
The Sega Dreamcast was a sixth-generation video game console released by Sega in 1999. It...سگا دریمکست یک کنسول بازی نسل ششم بود که توسط سگا در سال ۱۹۹۹ منتشر شد. این کنسول...
دستوری
Write a single paragraph that describes the Sega Dreamcast console and explains why it was so revolutionary.یک پاراگراف بنویس که کنسول سگا دریمکست را توصیف کند و توضیح دهد چرا اینقدر انقلابی بود.
وقتی از چند مثال آموزشی استفاده میکنید، کلاسها (دستهها) را مخلوط کنید.
مثال: اگر کلاسهای “مثبت” و “منفی” دارید، آنها را یکی در میان قرار دهید، نه اینکه همه مثبتها اول باشند و سپس همه منفیها.
چرا؟
اگر ترتیب مثالها همیشه یکسان باشد، مدل ممکن است فقط ترتیب را یاد بگیرد نه ویژگیهای اصلی هر کلاس. ترکیب کلاسها باعث میشود مدل در مواجهه با دادههای جدید بهتر عمل کند.
توصیه:
با حدود ۶ مثال آموزشی شروع کنید و دقت مدل را بسنجید. در صورت نیاز، مثالهای بیشتر اضافه کنید.
برای کارهای غیرخلاقانه مانند استخراج، مرتبسازی، رتبهبندی یا دستهبندی دادهها، بهتر است خروجی را به صورت ساختاریافته مانند JSON یا XML دریافت کنید.
خروجی همیشه با سبک و فرمت ثابت
تمرکز فقط روی دادههای مورد نیاز
کاهش احتمال خطا و “توهم” مدل
امکان مشخص کردن روابط بین دادهها
حفظ نوع دادهها (عدد، متن، تاریخ)
امکان مرتبسازی راحت دادهها
JSON پرحجمتر است و تعداد توکن بیشتری مصرف میکند → زمان پردازش و هزینه بالاتر
خروجی طولانی ممکن است ناقص شود (مثلاً یک آکولاد یا براکت بسته فراموش شود)
راه حل:
کتابخانههایی مانند json-repair در PyPI میتوانند JSON ناقص یا خرابشده را به شکل خودکار اصلاح کنند.
JSON Schema به شما اجازه میدهد ساختار ورودی JSON را مشخص کنید: چه فیلدهایی لازم است و نوع دادهها چیست.
مزایا:
تمرکز مدل روی اطلاعات مهم
کاهش احتمال اشتباه در تفسیر دادهها
مشخص کردن روابط بین بخشهای داده
امکان تعیین فیلدهای تاریخ و زمان با فرمت مشخص
اگر میخواهید توضیح محصولات یک فروشگاه اینترنتی را بسازید، به جای متن آزاد، میتوانید ویژگیهای محصول را با JSON Schema به مدل بدهید تا خروجی ساختاریافته و دقیق داشته باشید.
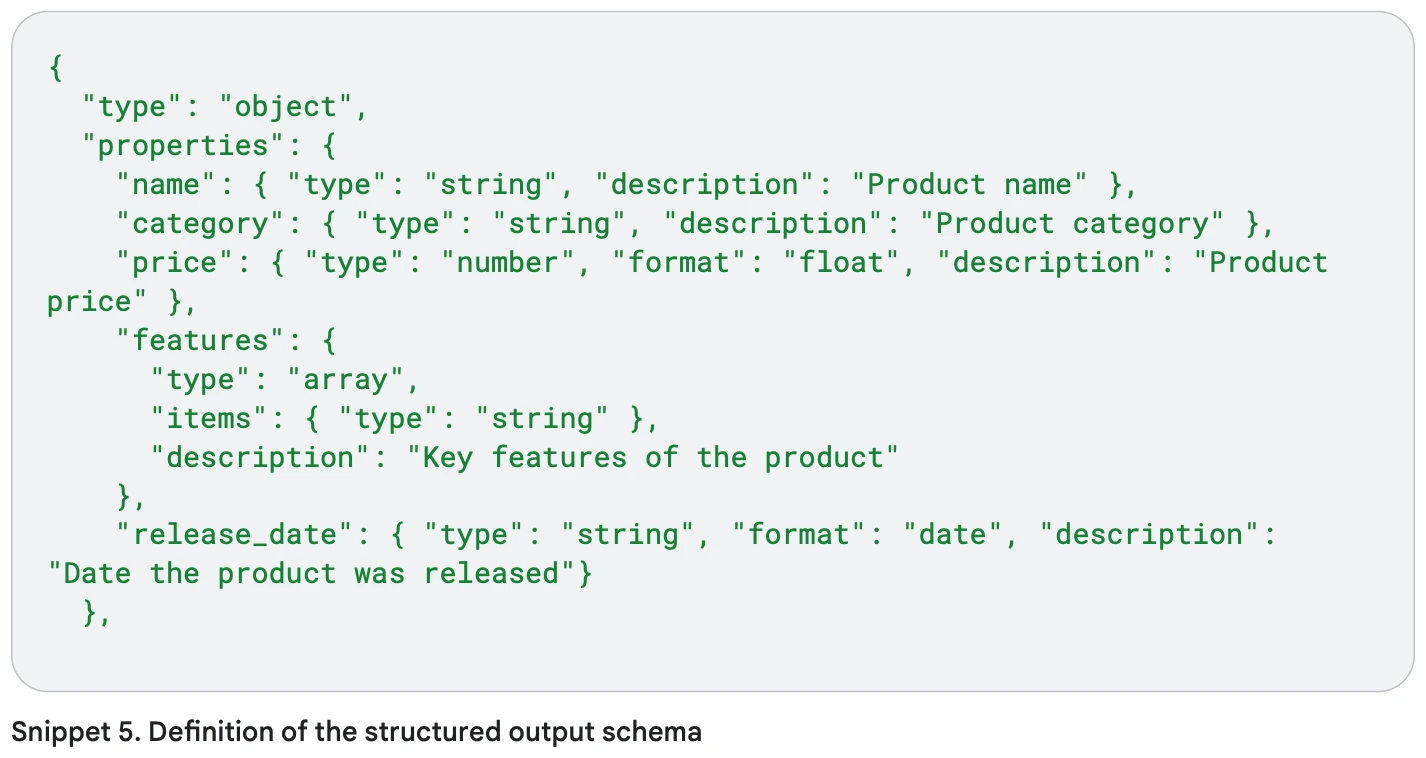
بعد از اینکه اسکیمای JSON رو مشخص کردید، حالا میتونید دادههای واقعی محصول رو بهصورت یه شیء JSON ارائه بدید که با اون اسکیمای تعریفشده هماهنگ باشه.
وقتی اسکیمای JSON و داده واقعی محصول را به مدل میدهید، مدل دقیقاً میفهمد هر فیلد چه معنایی دارد (مثلاً تاریخ عرضه، قیمت، ویژگیها).
این باعث میشود توضیحات تولیدشده دقیقتر، مرتبطتر و ساختاریافتهتر باشند.
این روش مخصوصاً زمانی مفید است که:
با حجم زیادی از داده کار میکنید
میخواهید مدلهای زبانی را در اپلیکیشنهای پیچیده استفاده کنید
میخواهید تمرکز مدل روی ویژگیهای مهم باشد
برای مسائل پیچیده از Chain of Thought (CoT) استفاده کنید تا مدل قدم به قدم استدلال کند.
نکته کلیدی: پاسخ نهایی را بعد از توضیح و استدلالها بنویسید. این کمک میکند اطلاعات مورد استفاده برای حدس پاسخ دقیقتر شود.
وقتی CoT را با Self-consistency ترکیب میکنید، حتماً پاسخ نهایی را از متن استدلالها جدا کنید تا مستقل و قابل اتکا باشد.
تنظیمات پیشنهادی:
دما (Temperature) = 0، چون CoT معمولاً یک پاسخ درست دارد و پیشبینی ساده و مستقیم بهترین است.
همه پرامپتها و نتایج آنها را مستند کنید:
چه چیزی خوب کار کرده؟
چه چیزی نتیجه مطلوب نداده؟
این کار باعث میشود بتوانید روشها و پرامپتهای موفق را تکرار کنید و کارایی مدل را افزایش دهید.

مهندسی پرامپت یک مهارت است که با تمرین و آزمایش بهبود مییابد. با استفاده از بهترین شیوههای ذکر شده در این راهنما، میتوانید پرامپتهایی ایجاد کنید که نتایج بهتری از مدلهای زبانی بزرگ تولید میکنند.
به یاد داشته باشید:
با تمرین و آزمایش مداوم، مهارتهای مهندسی پرامپت شما به طور قابل توجهی بهبود خواهد یافت.
در این بخش، برخی از کاربردهای عملی مهندسی پرامپت را بررسی میکنیم که میتوانید در پروژههای خود از آنها استفاده کنید.
Summarize the following article in 3-5 sentences while preserving the key information: {{ARTICLE_TEXT}}
Create a blog post about the benefits of meditation for mental health. The post should be approximately 500 words, include an introduction, 3 main benefits with supporting evidence, and a conclusion.
Analyze the sentiment of the following customer reviews and classify each as POSITIVE, NEGATIVE, or NEUTRAL: 1. "The product arrived on time and works perfectly. Very satisfied with my purchase." 2. "Decent quality but the price is too high compared to similar products." 3. "Absolutely terrible experience. The item was damaged and customer service was unhelpful."
Extract the following information from this resume: - Name - Email - Phone number - Education history (institution, degree, dates) - Work experience (company, position, dates) - Skills Format the output as JSON. {{RESUME_TEXT}}
Create a Python function that reads a CSV file containing student data (name, age, grade) and returns the average grade for each age group. Include error handling and comments.
Translate the following text from English to Spanish, maintaining the same tone and style: {{TEXT_TO_TRANSLATE}}
Answer the following questions about quantum computing: 1. What is a qubit? 2. How does quantum entanglement work? 3. What are the potential applications of quantum computing? 4. What are the current limitations of quantum computers? Provide detailed but accessible explanations for someone with a basic understanding of physics.
Create a detailed outline for a research paper on the impact of artificial intelligence on healthcare. Include main sections, subsections, and key points to address in each section.
مهندسی پرامپت یکی از مهارتهای کلیدی برای کار با مدلهای زبانی بزرگ (LLMها) است. با این مهارت میتوانید پاسخهای دقیق، مرتبط و مفیدی از مدلها دریافت کنید.
واضح و دقیق باشید: دستورالعملهایتان باید روشن و بدون ابهام باشند.
از مثالها استفاده کنید: مخصوصاً برای وظایف پیچیده، مثالهای واضح کمک میکنند مدل الگو را درک کند.
فرمت خروجی را مشخص کنید: مدل را راهنمایی کنید که پاسخها را به چه شکل و ساختاری بدهد (مثلاً JSON).
از تکنیکهای پیشرفته استفاده کنید: برای مسائل دشوار از روشهایی مثل زنجیره تفکر (CoT) یا درخت تفکرات (ToT) بهره ببرید.
تنظیمات مدل را بهینه کنید: با تغییر دما (Temperature)، Top-K و Top-P میتوانید تعادل بین خلاقیت و دقت را کنترل کنید.
آزمایش و تکرار کنید: پرامپتها و نتایجشان را مستندسازی کنید، ارزیابی کنید و بر اساس بازخورد بهبود دهید.
با پیشرفت فناوری LLM، مهندسی پرامپت هم در حال تکامل است. بهروز ماندن با تکنیکهای جدید و بهترین شیوهها باعث میشود از این ابزارهای قدرتمند به بهترین شکل استفاده کنید.